鸟巢采集快速开始
准备
1.注册NewCrawler账号
2.安装鸟巢采集客户端应用
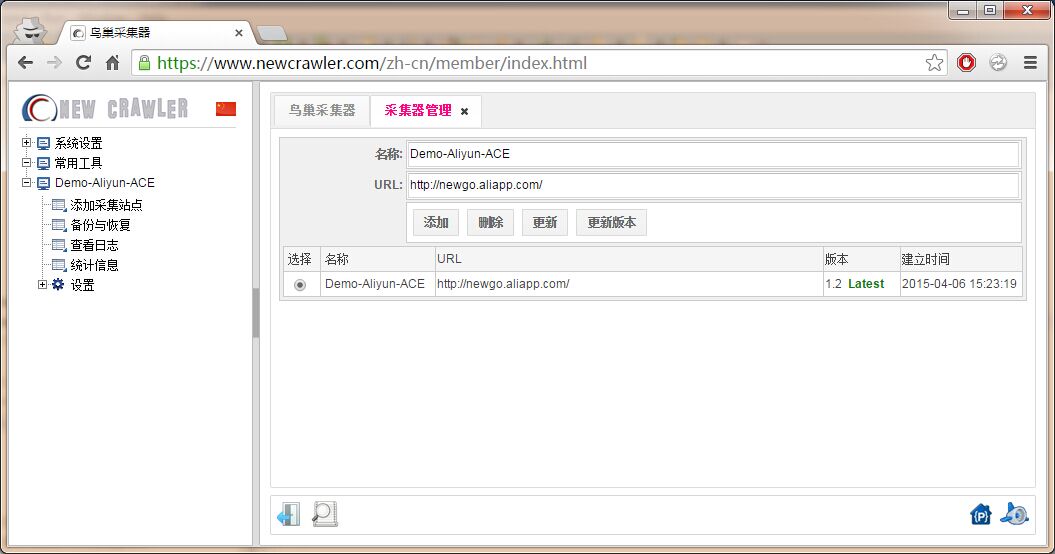
3.添加客户端应用到鸟巢采集WEB服务端
进入 `系统设置` > `采集器管理` 添加客户端应用
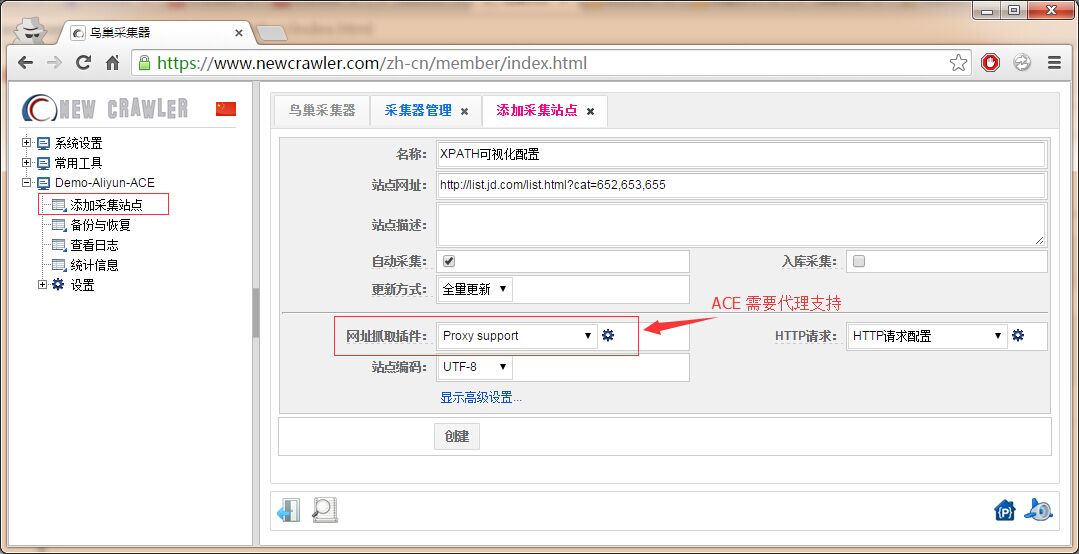
添加采集任务
进入刚添加的采集器节点,点击 `添加采集站点`
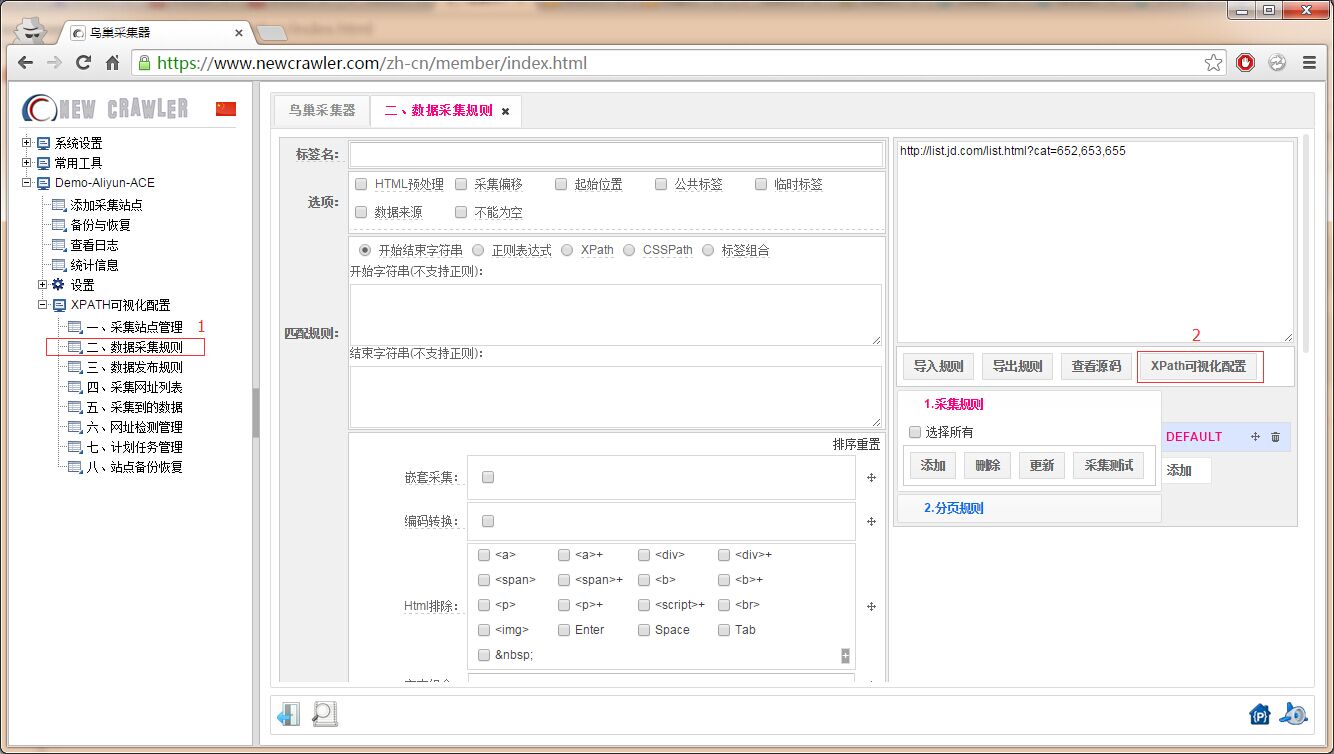
配置数据采集规则
1.打开 XPath可视化配置
进入上一步添加的采集站点,点击 `数据采集规则` ,再点击 `XPath可视化配置`
2.设置抓取规则
选中要抓取的字段
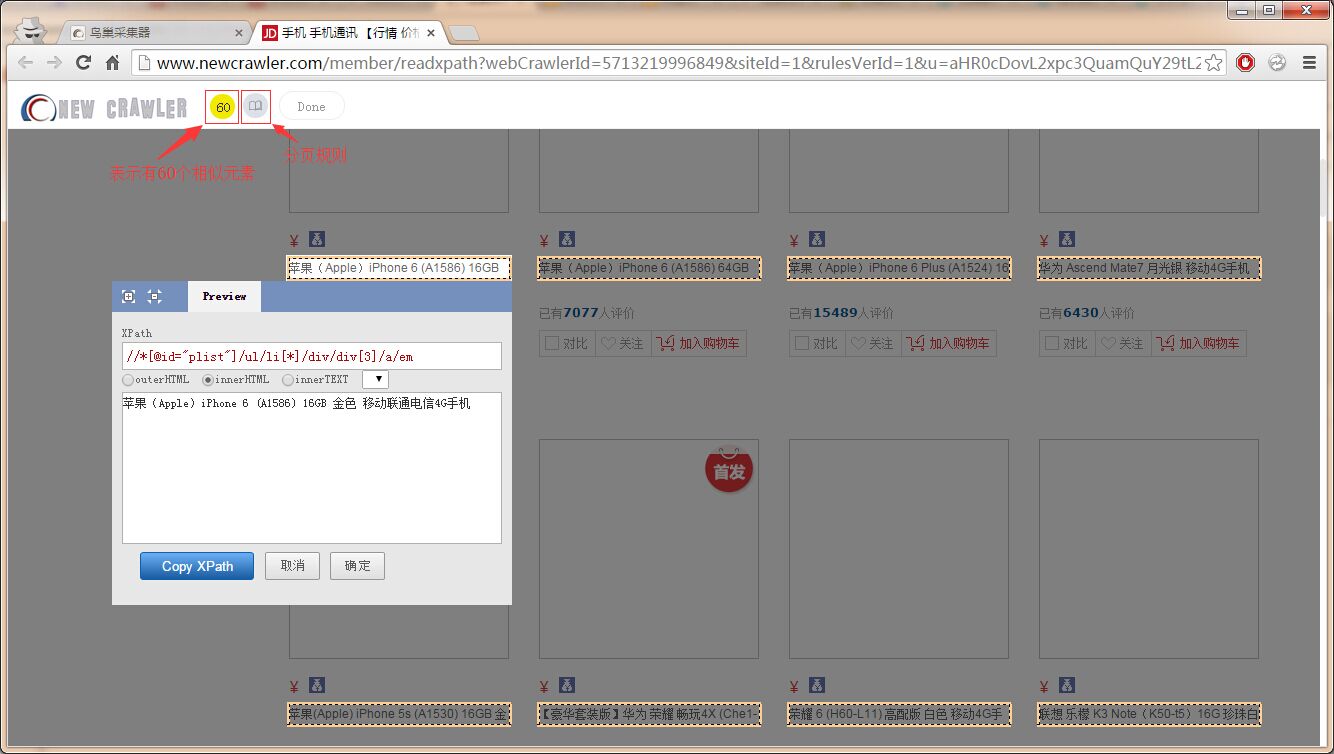
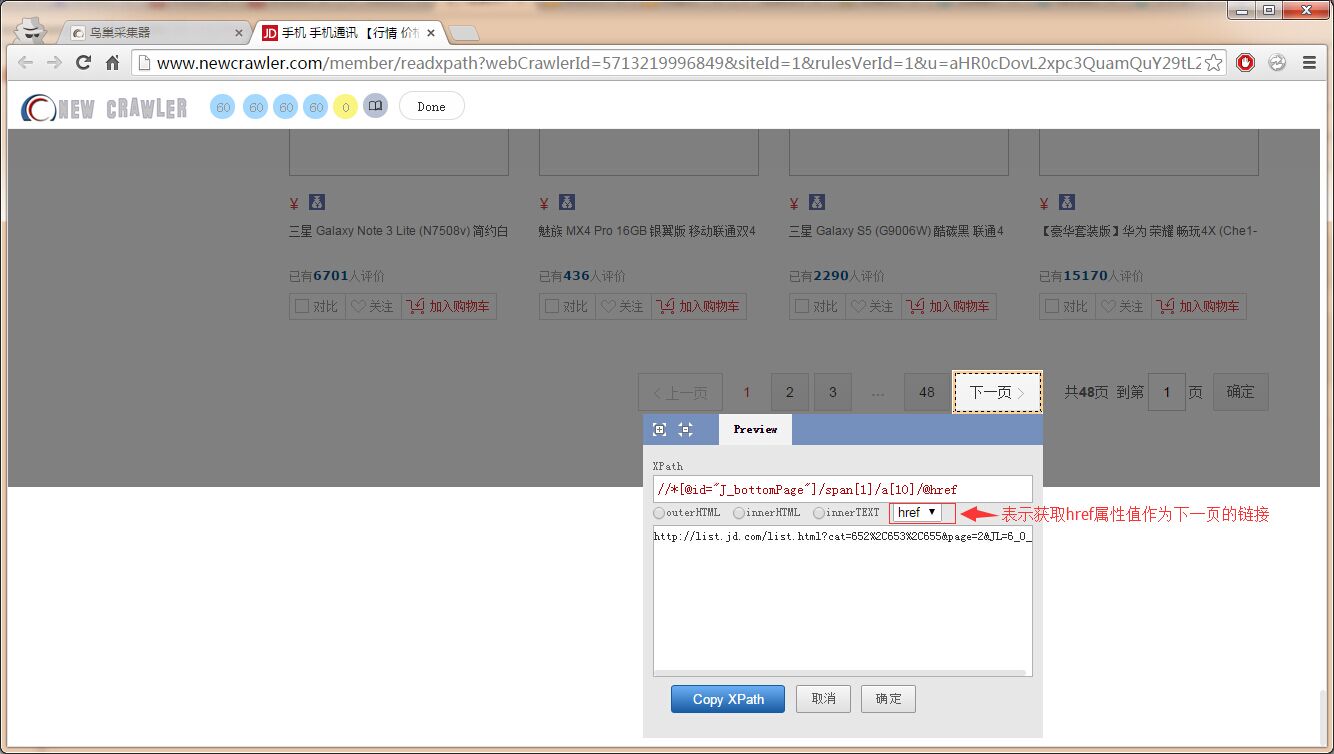
如果有下一页,设置好下一页链接提取规则
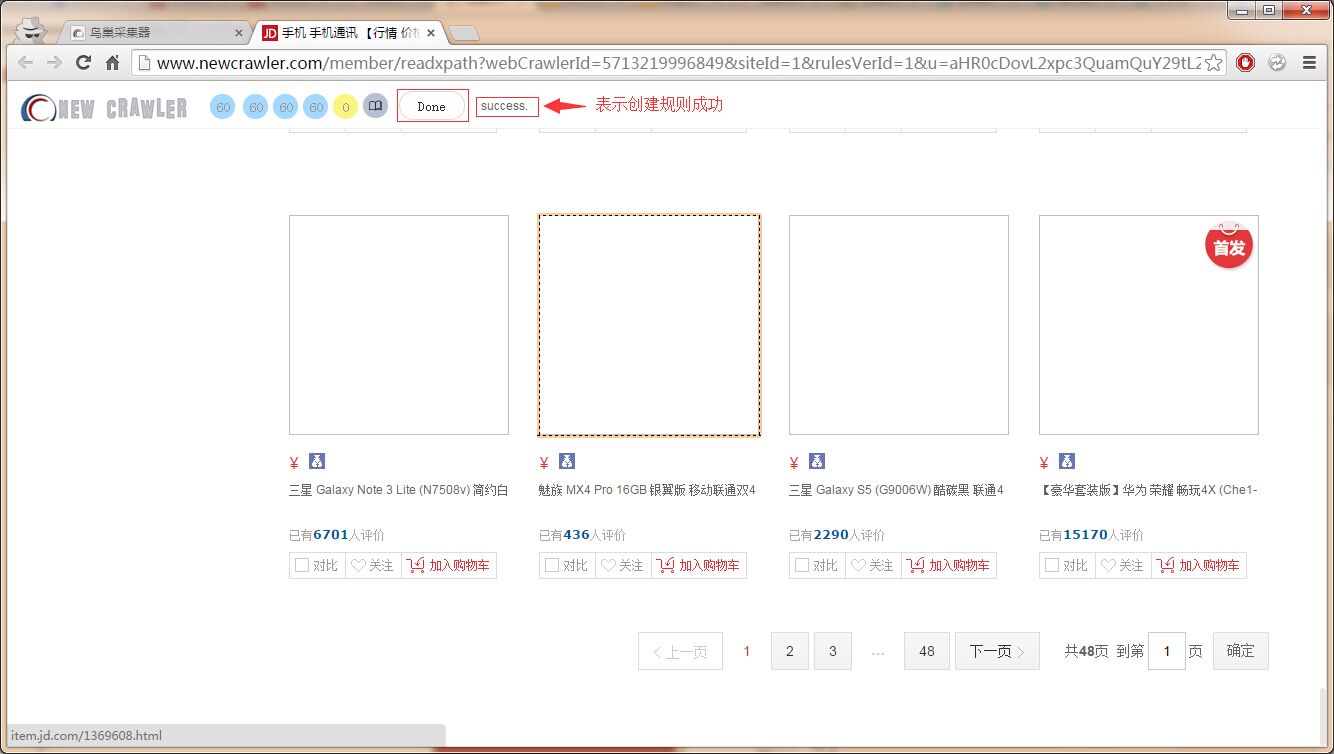
最后点击 `Done` 提示 `success` 表示创建规则成功
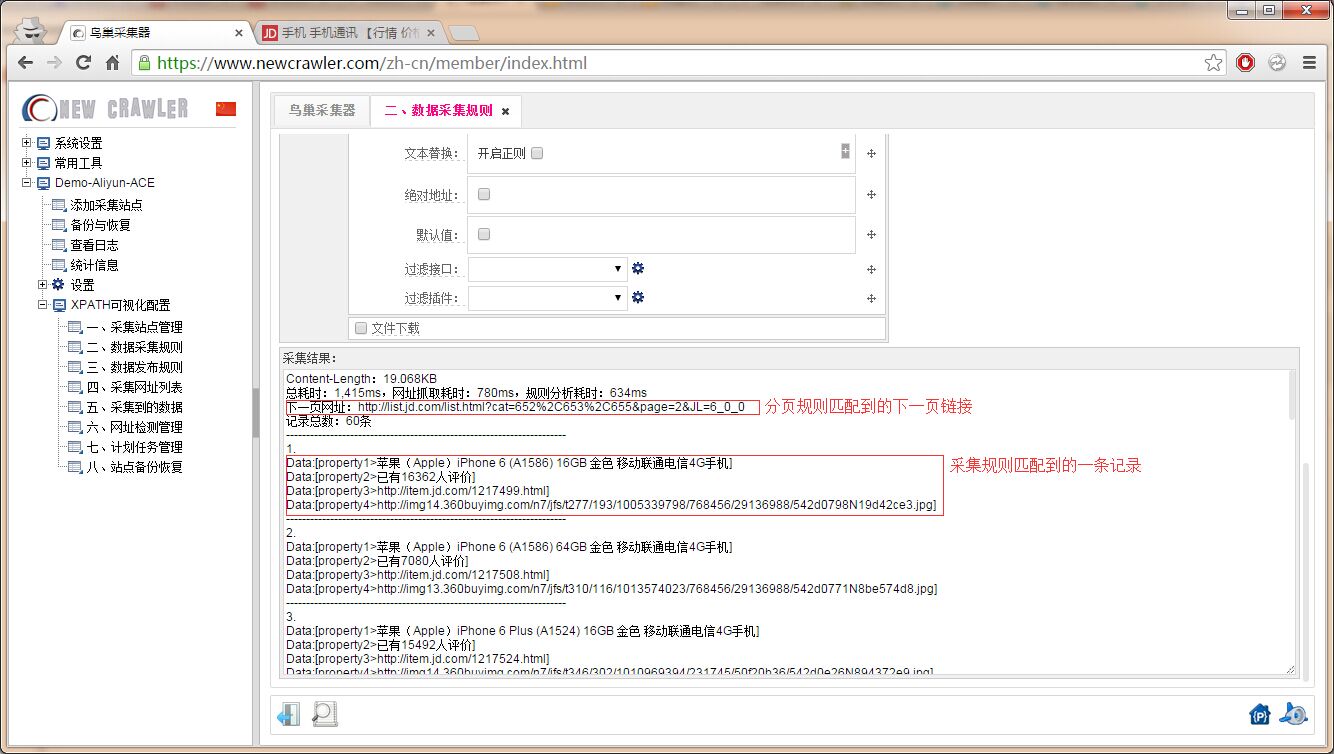
3.抓取测试
重新点击 `数据采集规则` 刷新数据采集规则页面,可以在 `采集规则` 区域看到自动添加的规则
点击 `采集测试` 可以看到抓取结果
添加采集网址
进入 `采集网址列表` 页面,点击 `添加网址` ,在 `网址批量添加` 区域中输入网址然后点击 `添加网址`
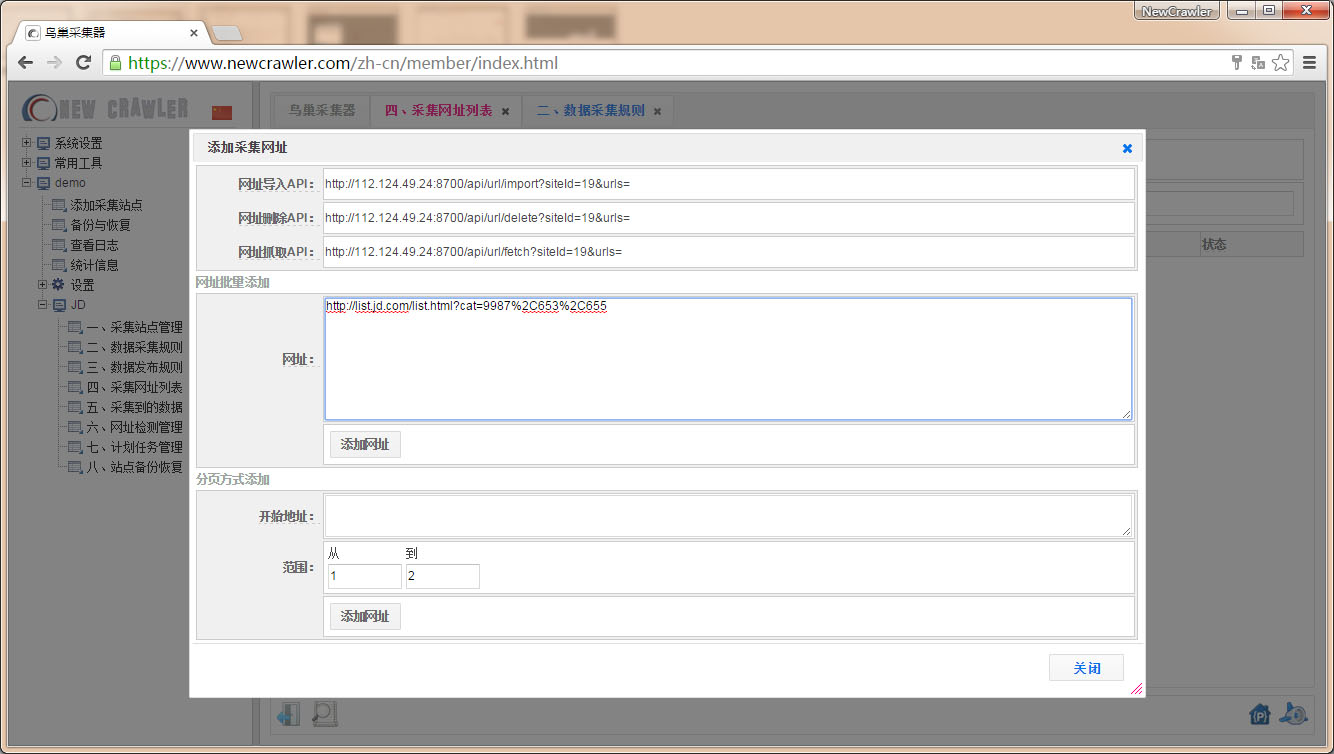
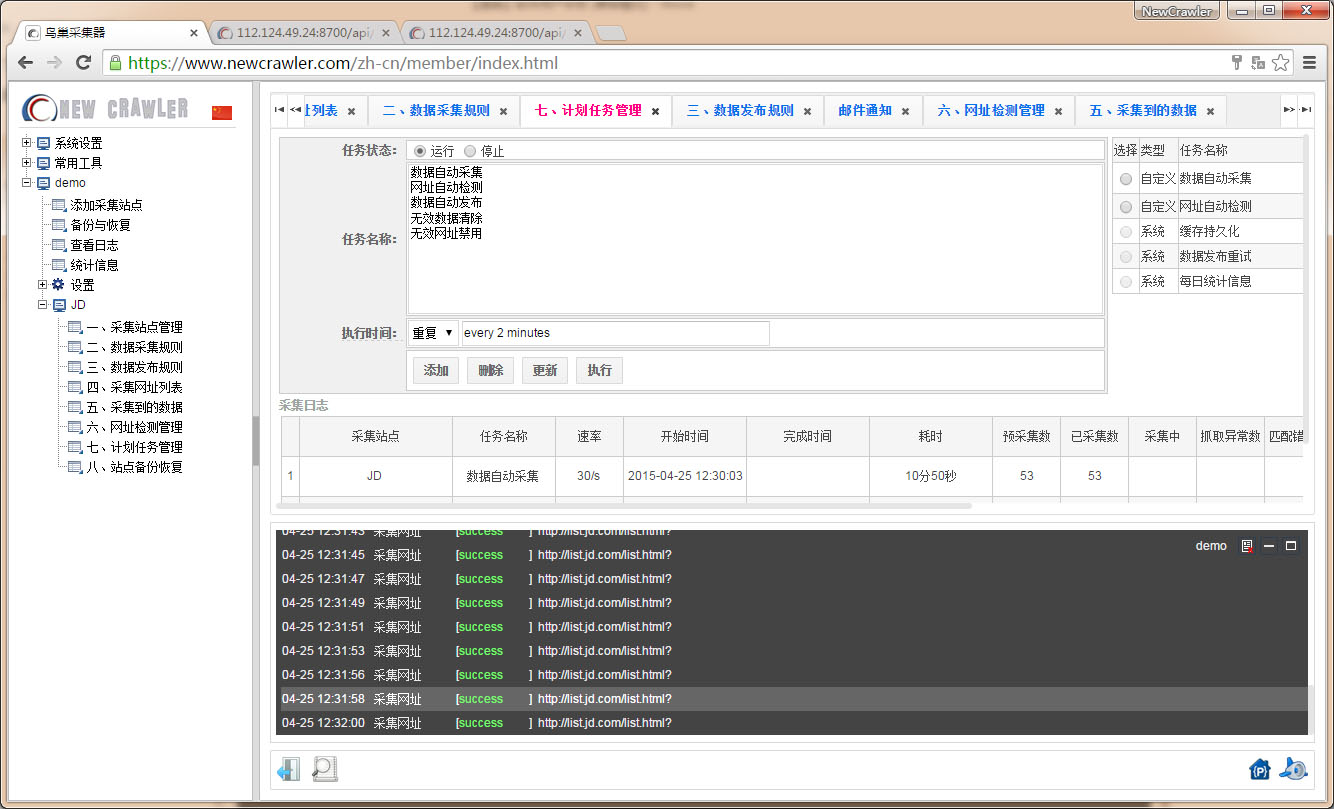
配置计划任务自动采集
进入 `计划任务管理` 页面,选择 `数据自动采集` ,设置 `执行时间` 可以循环或定时执行,如 `重复` `every 1 hours` 表示每1小时执行一次
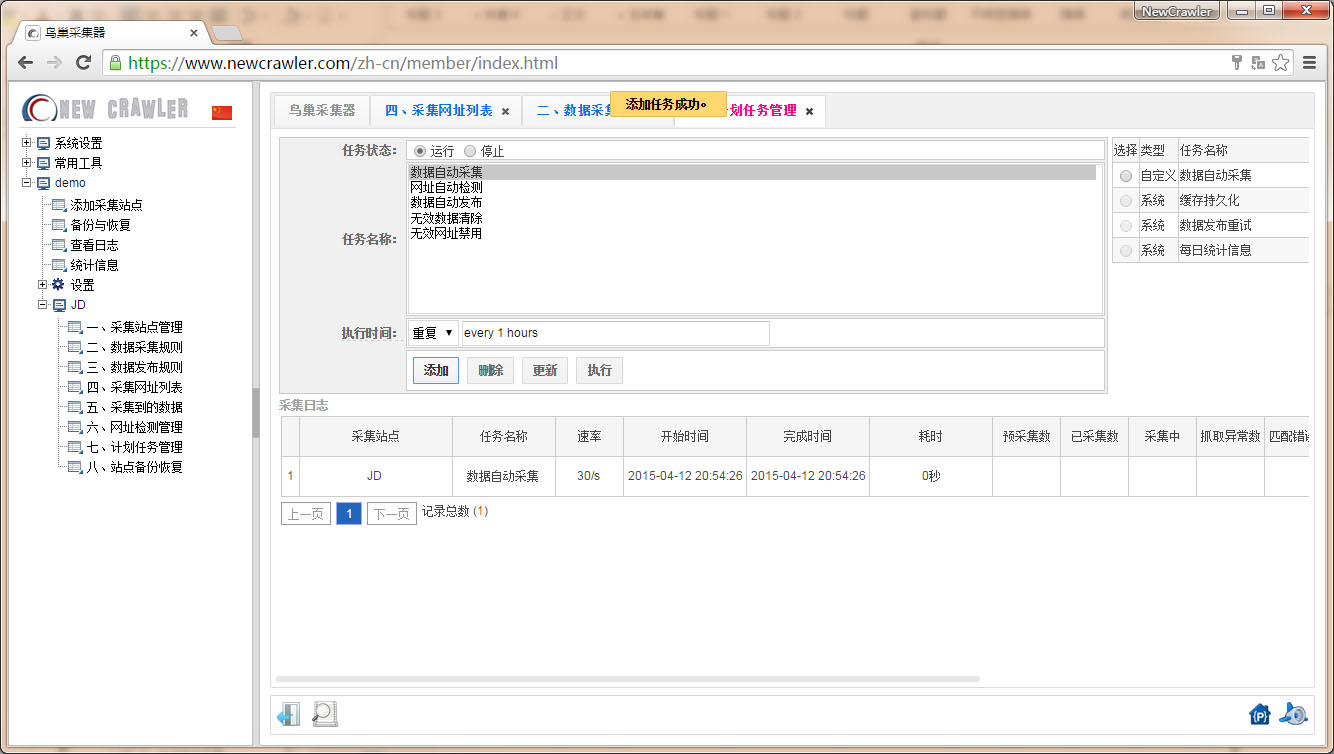
配置数据发布规则
进入 `数据发布规则` 页面,配置发布规则后点击 `添加`
采集规则有效性监控并使用邮件通知
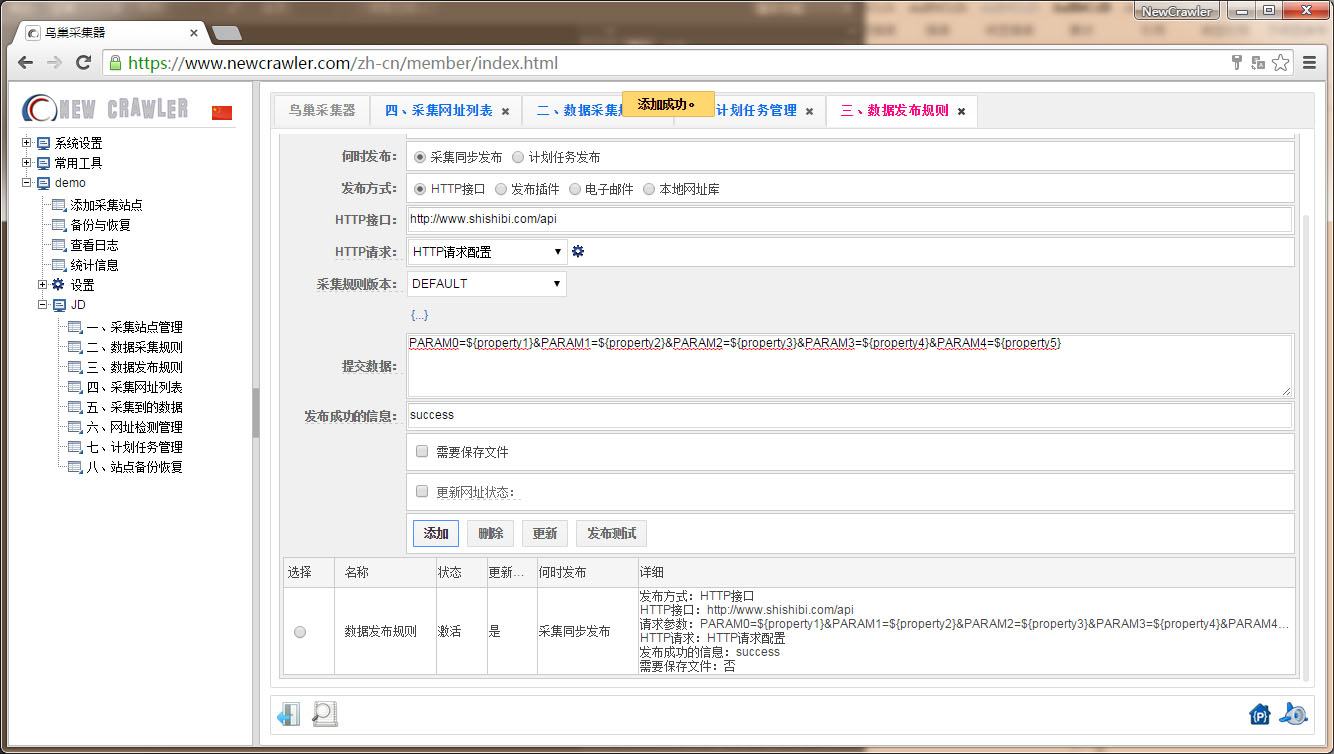
配置邮件通知模板
点击设置,进入 `邮件通知` 页面,配置邮件通知模板如 `采集规则监控` 后点击 `添加`
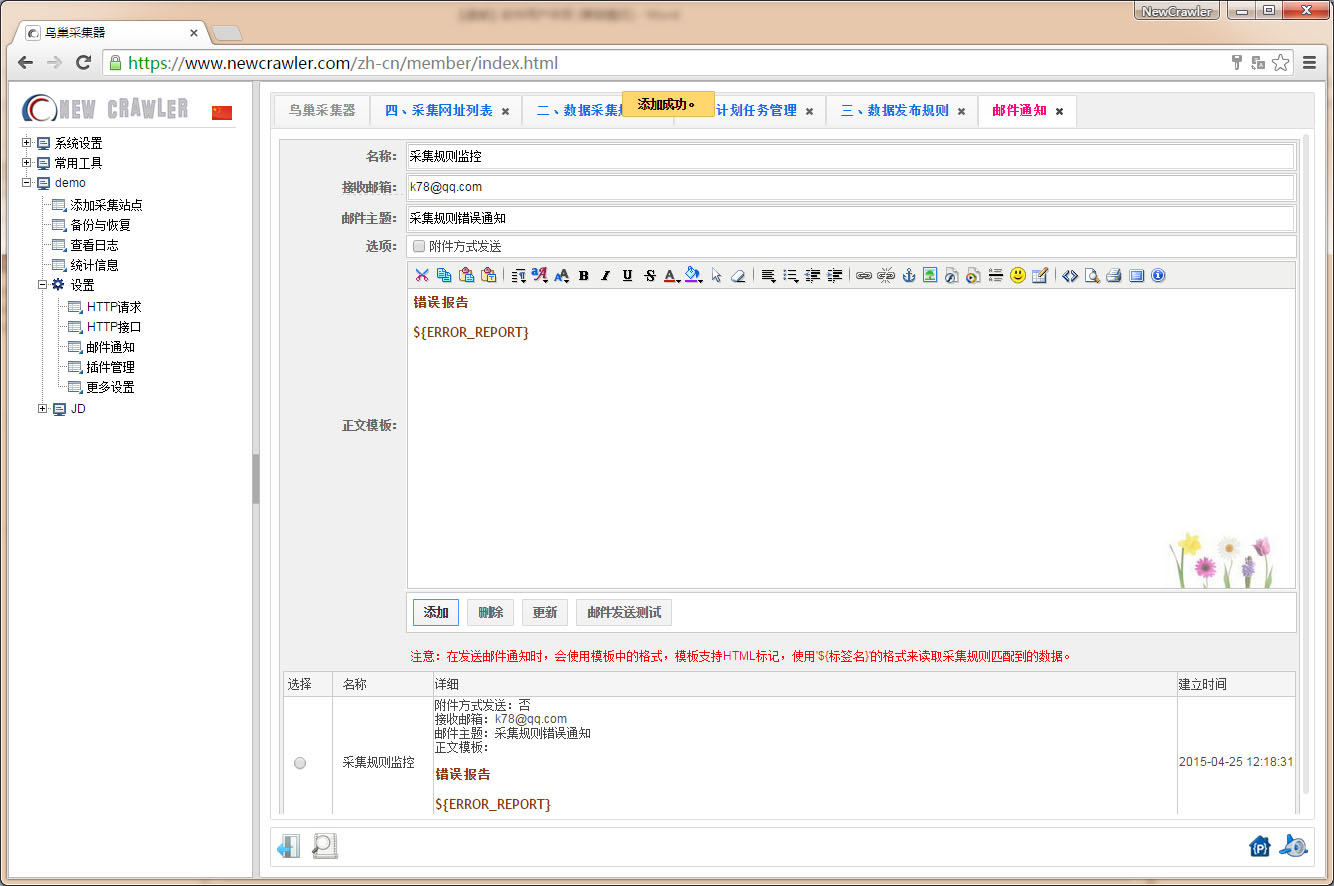
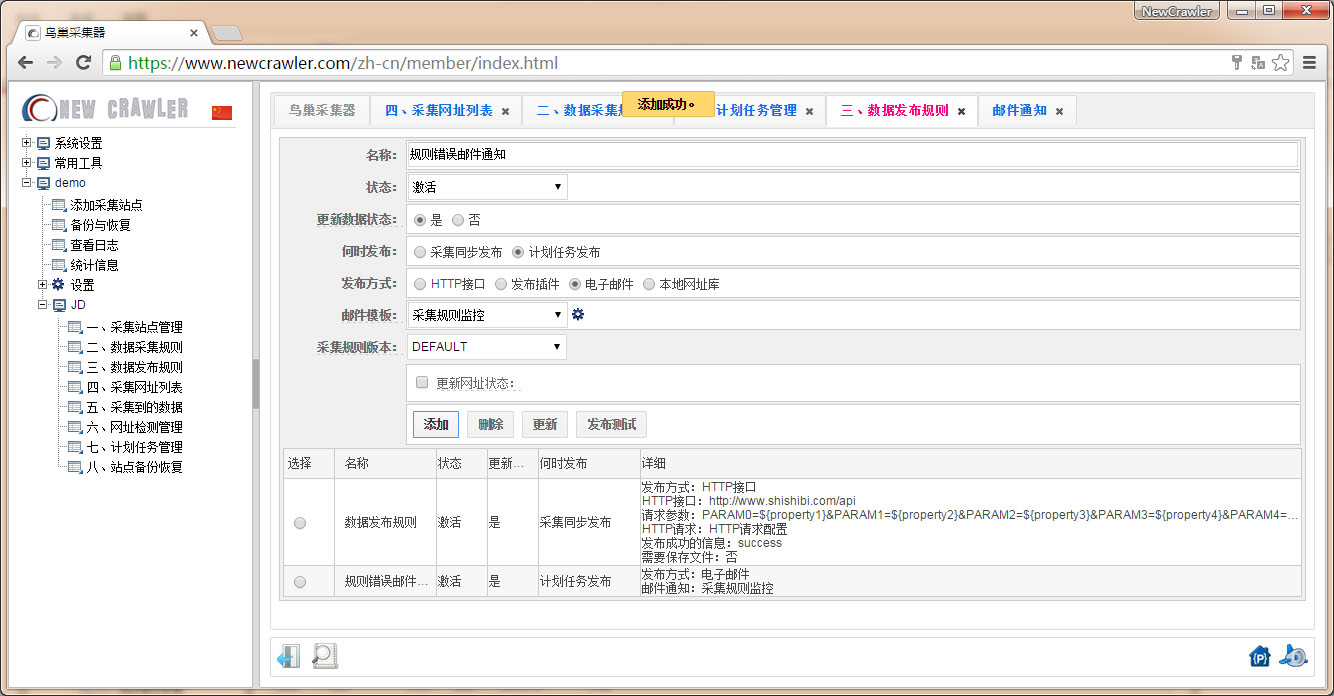
配置数据发布规则
进入 `数据发布规则` 页面,配置发布规则如 `邮件通知` 后点击 `添加`
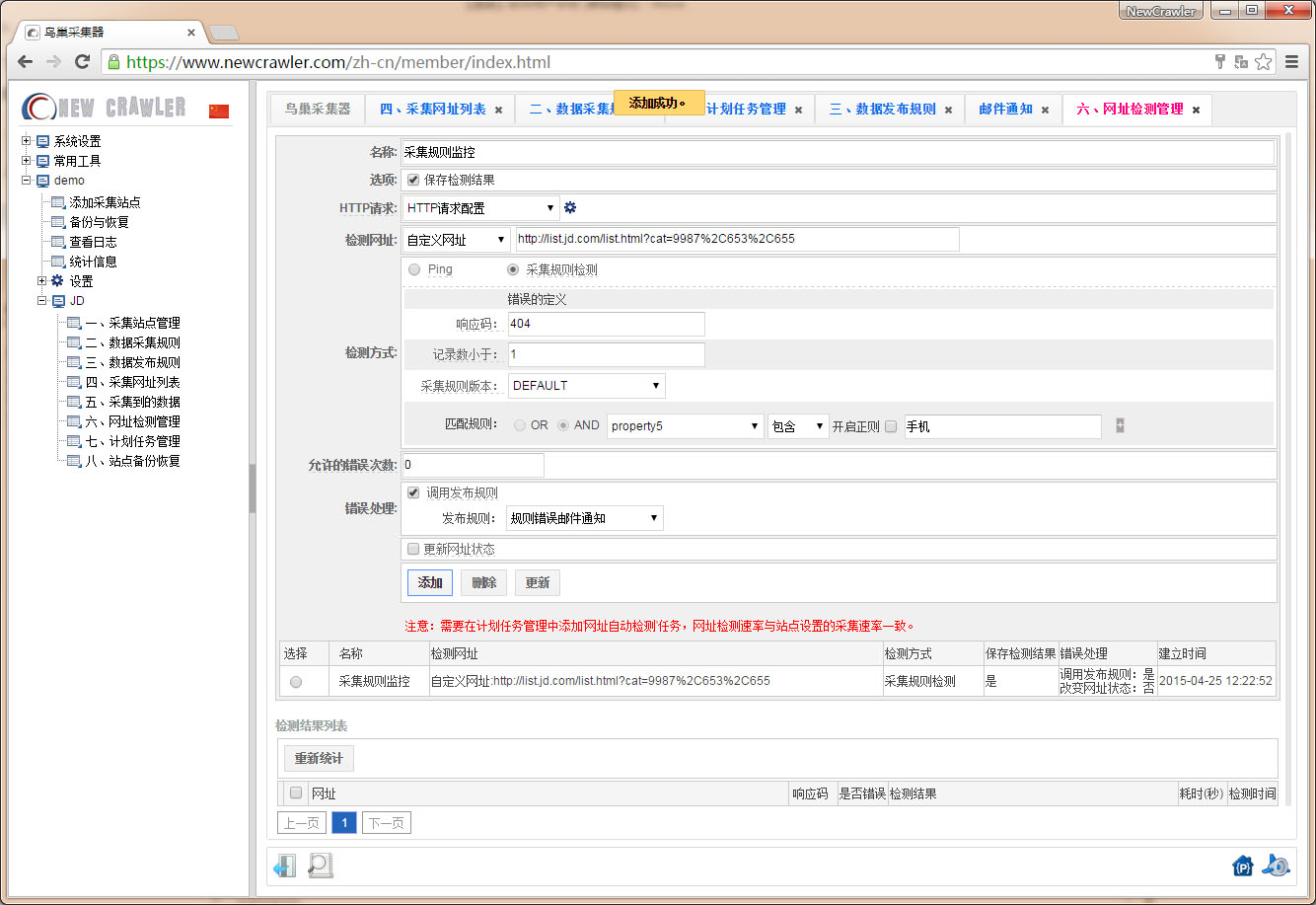
配置网址检测规则
进入 `网址检测管理` 页面,配置网址检测规则如 `采集规则监控` 后点击 `添加`
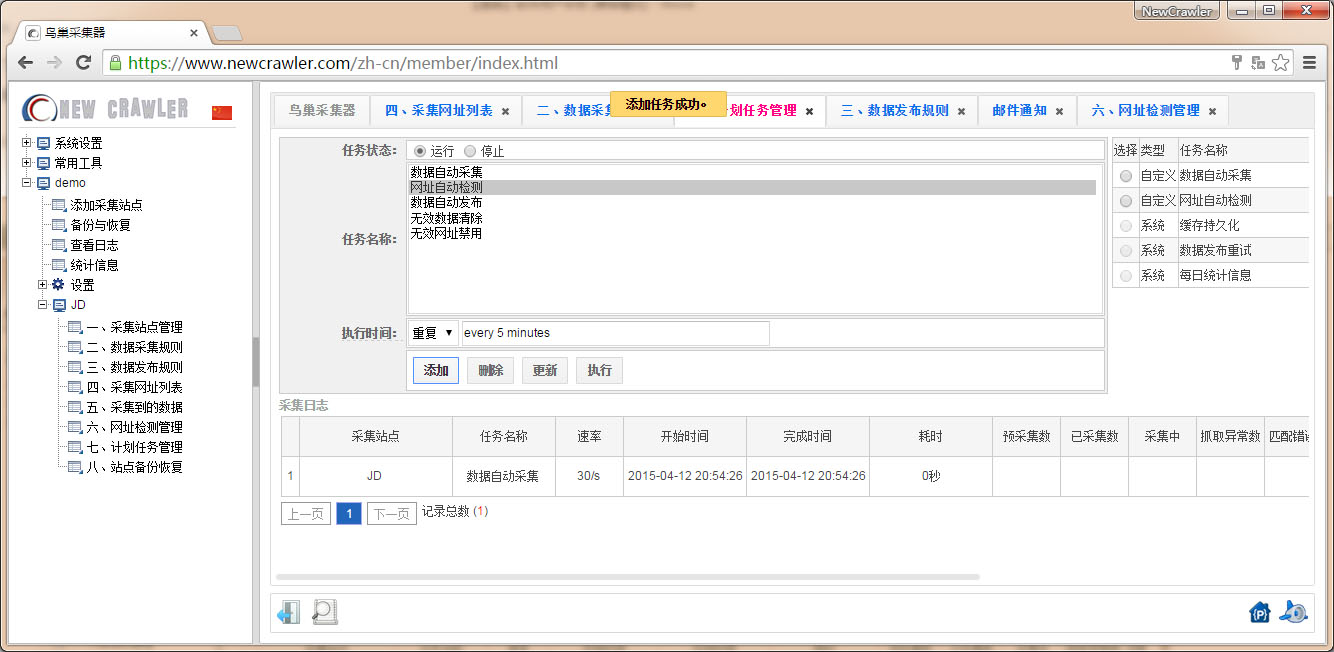
配置网址自动检测计划任务
进入 `计划任务管理` 页面,选择 `网址自动检测` ,设置 `执行时间` 可以循环或定时执行,如 `重复` `every 5 minutes` 表示每5分钟执行一次
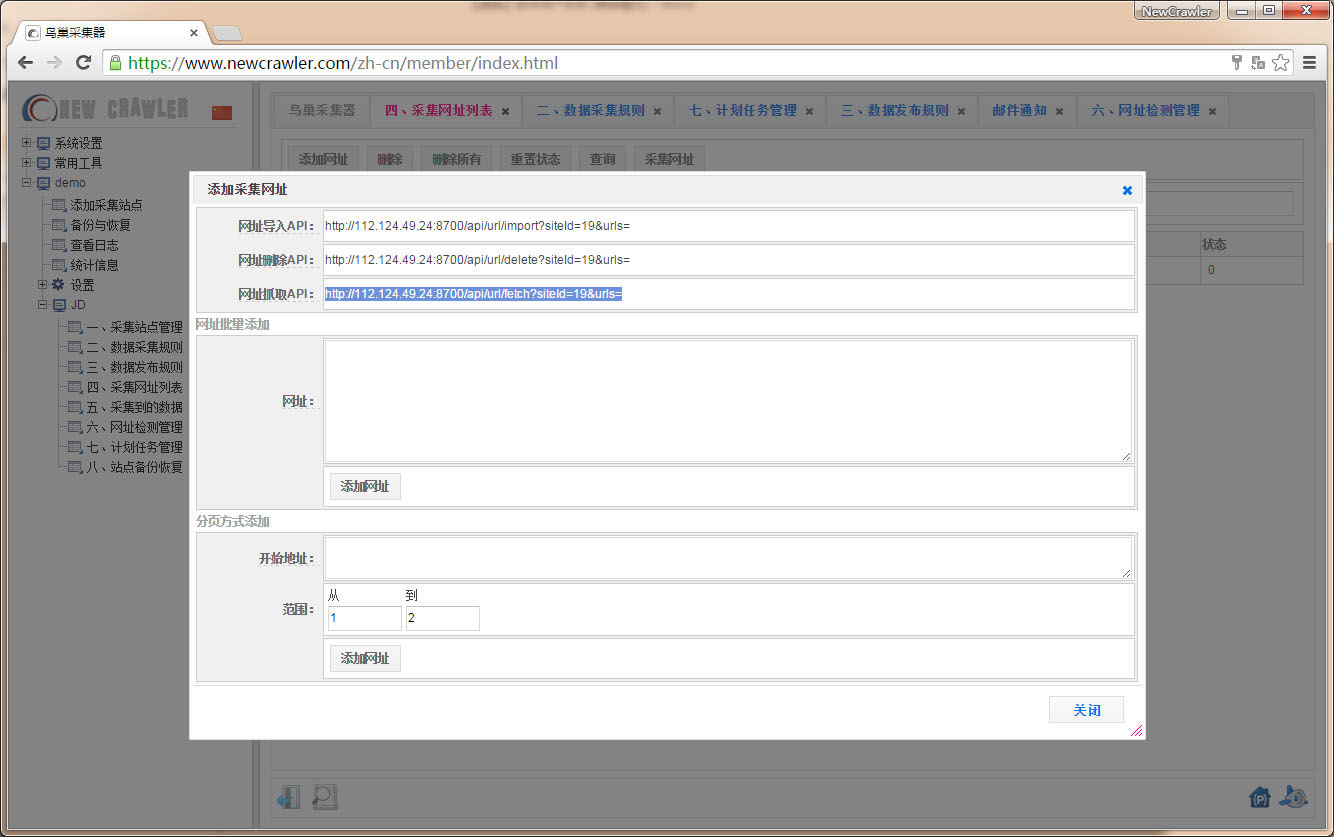
使用同步采集API
进入 `采集网址列表` 页面,点击 `添加网址` ,查看采集API `http://112.124.49.24:8700/api/url/fetch?siteId=19&urls=`
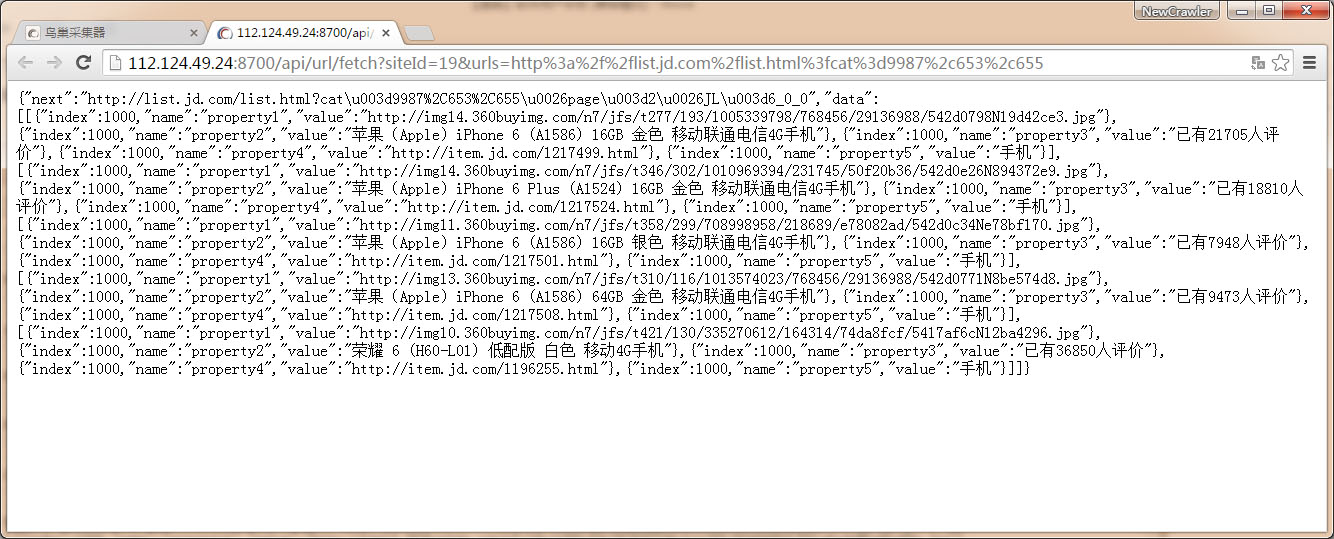
使用采集API `http://112.124.49.24:8700/api/url/fetch?siteId=19&urls=http%3a%2f%2flist.jd.com%2flist.html%3fcat%3d9987%2c653%2c655`
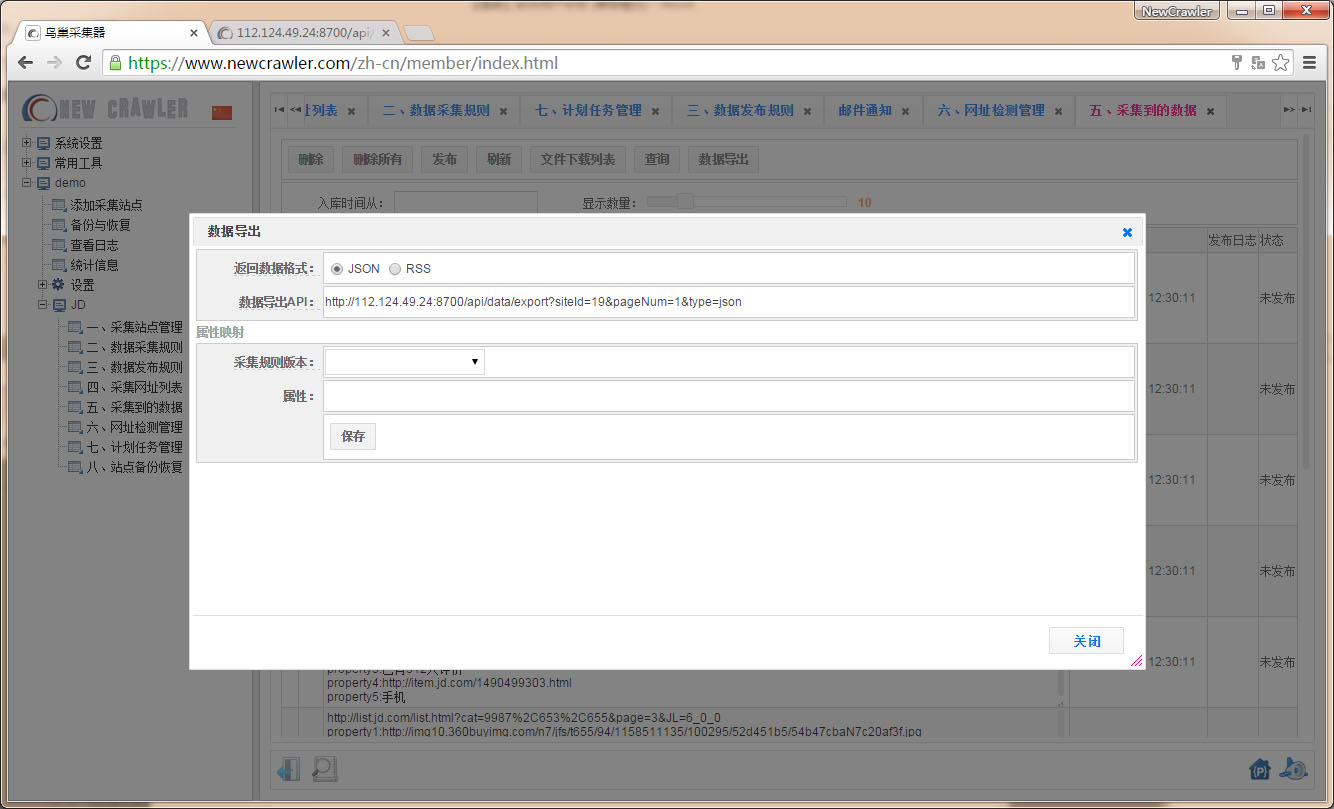
使用数据导出API
进入 `采集到的数据` 页面,点击 `数据导出` ,查看数据导出API `http://112.124.49.24:8700/api/data/export?siteId=19&pageNum=1&type=json`
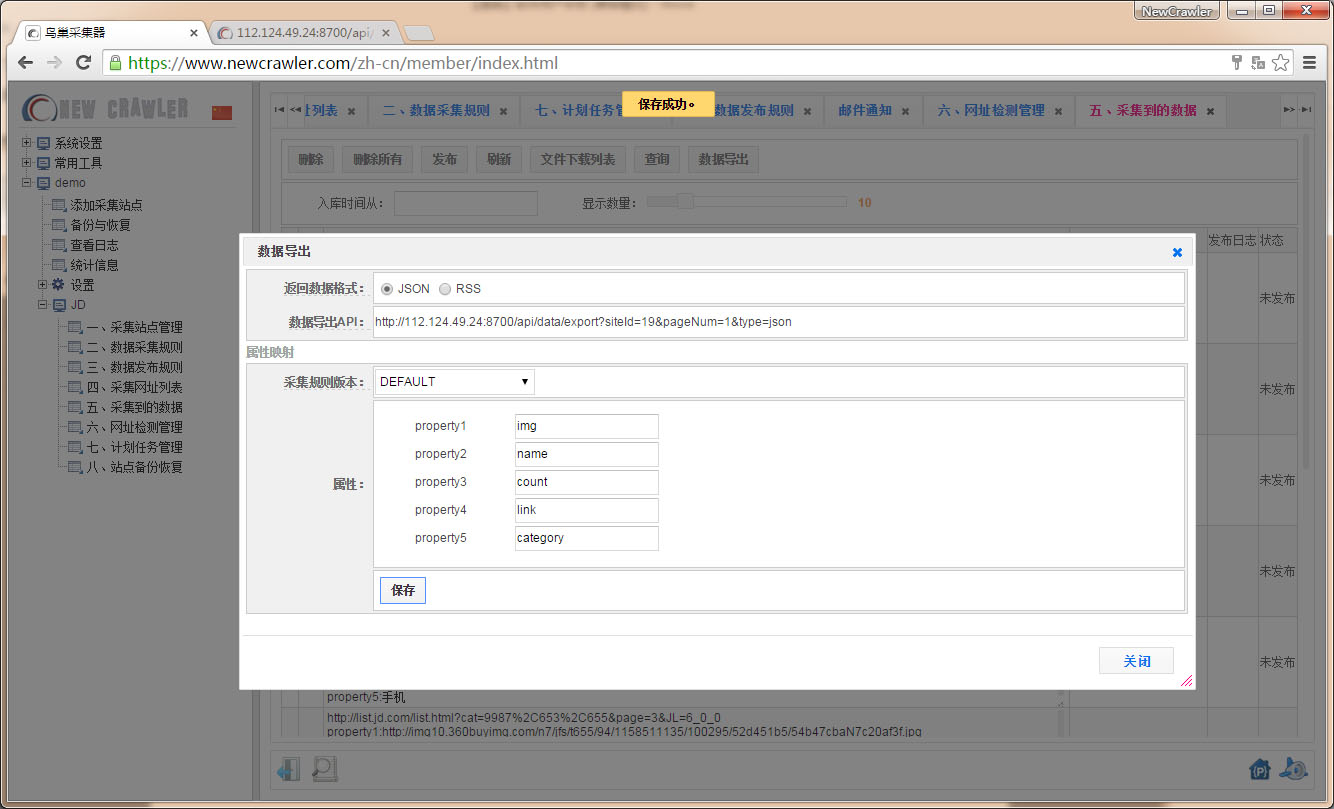
设置 `属性映射` ,点击 `保存`
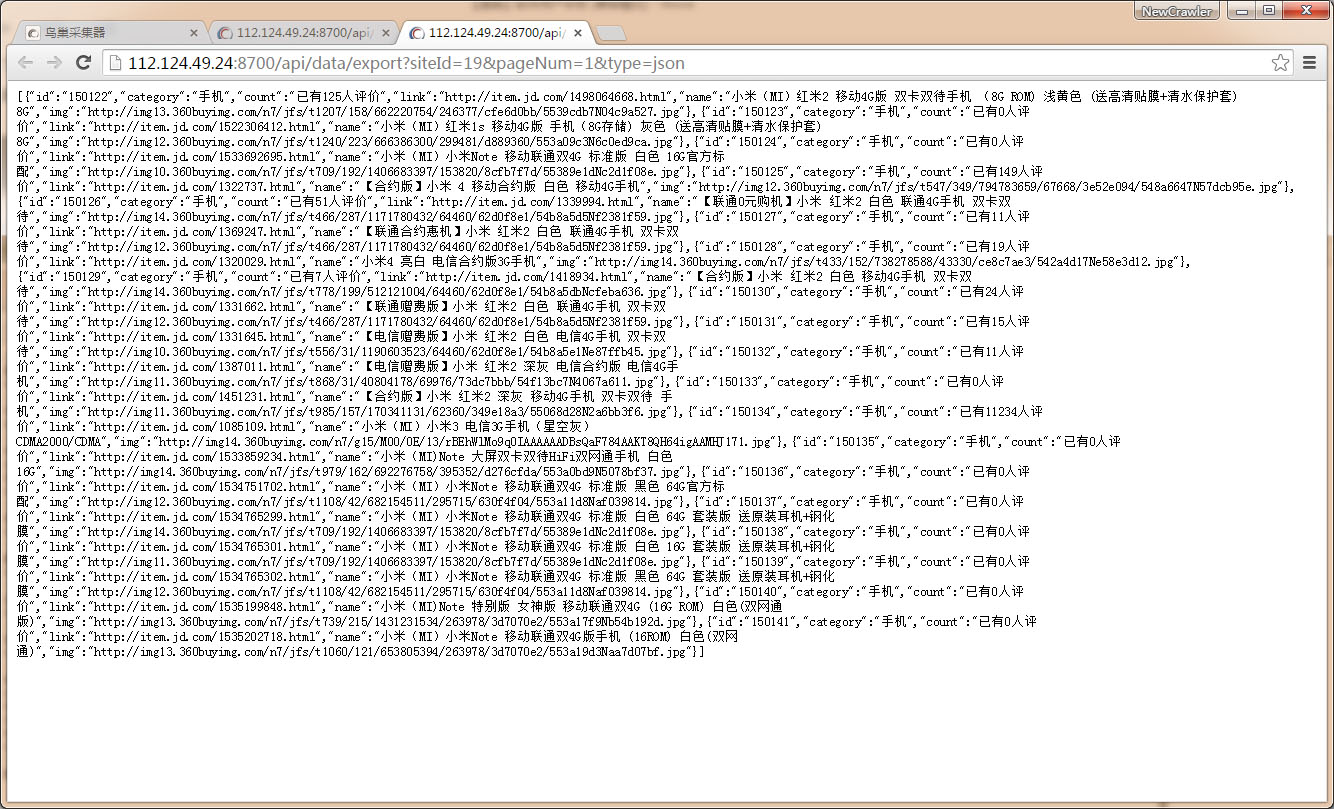
使用数据导出API `http://localhost:8600/api/data/export?siteId=1&pageNum=1&type=json`
查看实时采集日志
点击底部的显示日志图标 ,开启实时日志查看,再次点击底部的显示日志图标 ,将关闭实时日志查看。
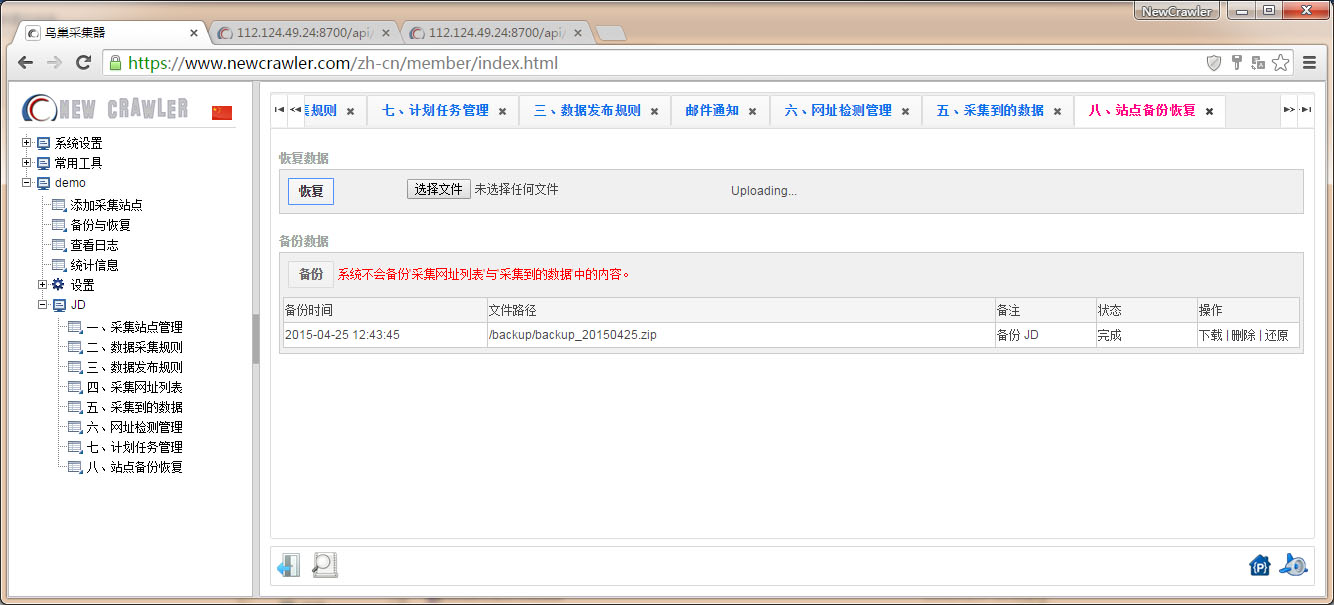
采集规则备份与恢复
进入 `站点备份恢复` 页面,点击 `备份` ,将备份采集任务的所有配置信息,不包括 `采集网址列表` 与 `采集到的数据`
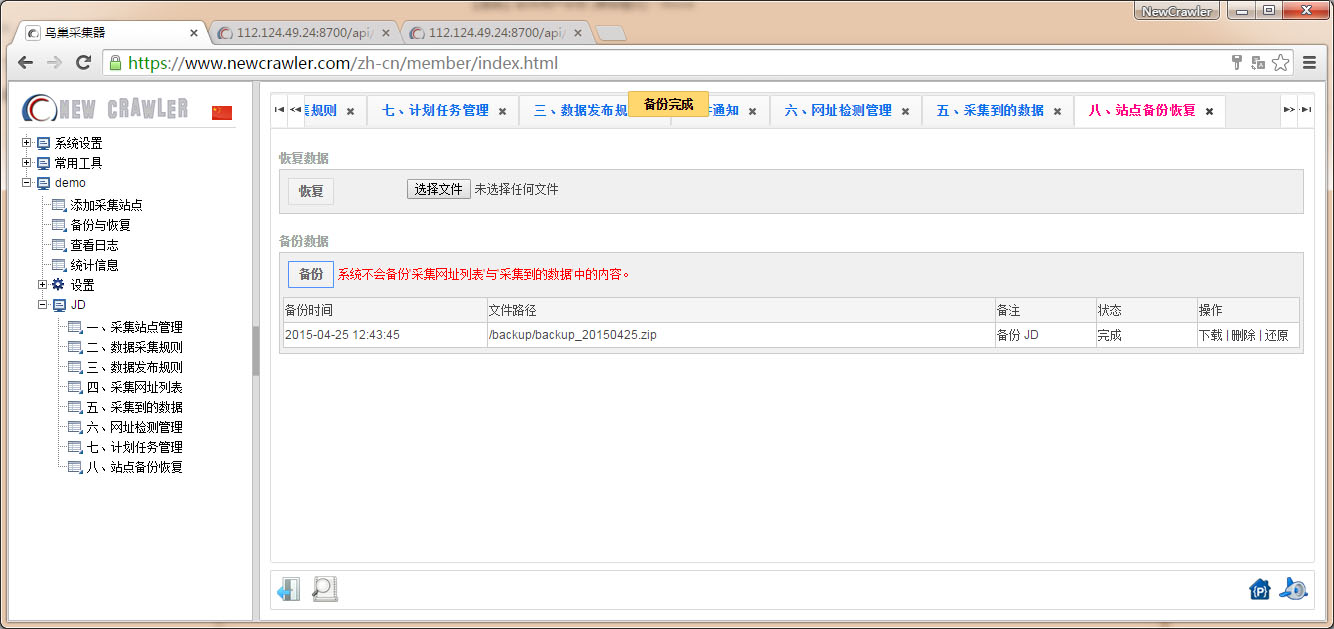
进入 `站点备份恢复` 页面,选择备份的压缩包,点击 `恢复` ,可以恢复所备份采集任务的所有配置信息